基于双活互备的 DR 解决方案
RPO
在 GreptimeDB 的“双活互备”架构中,有两个节点,分别独立部署了 GreptimeDB 服务。这两个节点都可以提供客户端执行读写的能力。然而,为了达到 RTO 和 RPO 的目标,我们需要对两节点进行一些配置。首先我们介绍一下在“双活互备”架构中读写的模式。
对于读操作:
SingleRead:读操作只在一个节点上执行,结果直接返回给客户端。DualRead:读操作在两个节点上都执行,结果将会合并去重后返回给客户端。
下图展示了这两种读操作模式的区别:
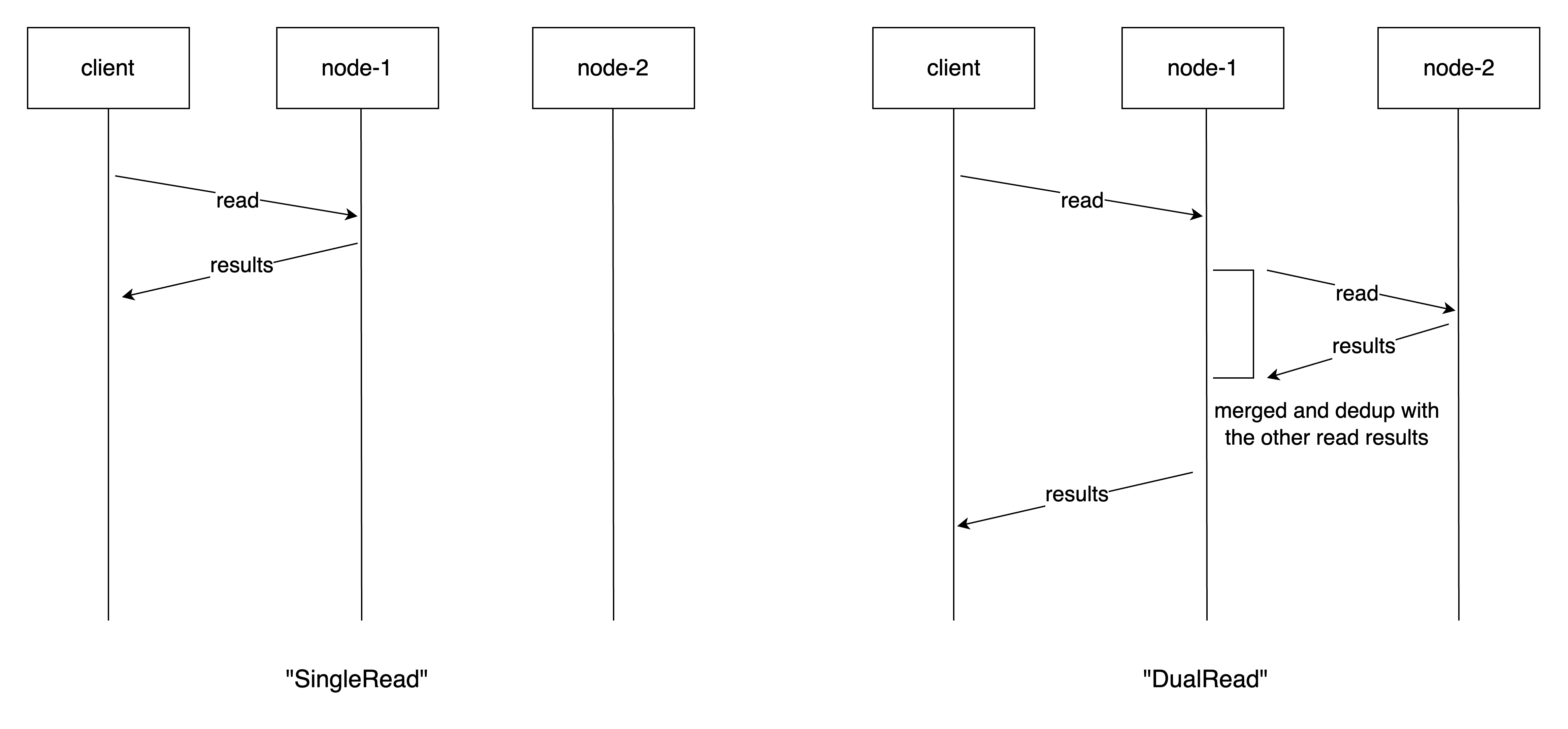
对于写操作:
SyncWrite:写操作在两个节点上都执行,只有在两个节点都写成功后才会返回给客户端(成功)。AsyncWrite:写操作仍然在两个节点上执行,但是在发起节点写成功后就会返回给客户端。另一个节点会异步地从发起节点接收写操作的复制。
下图展示了这两种写操作模式的区别:
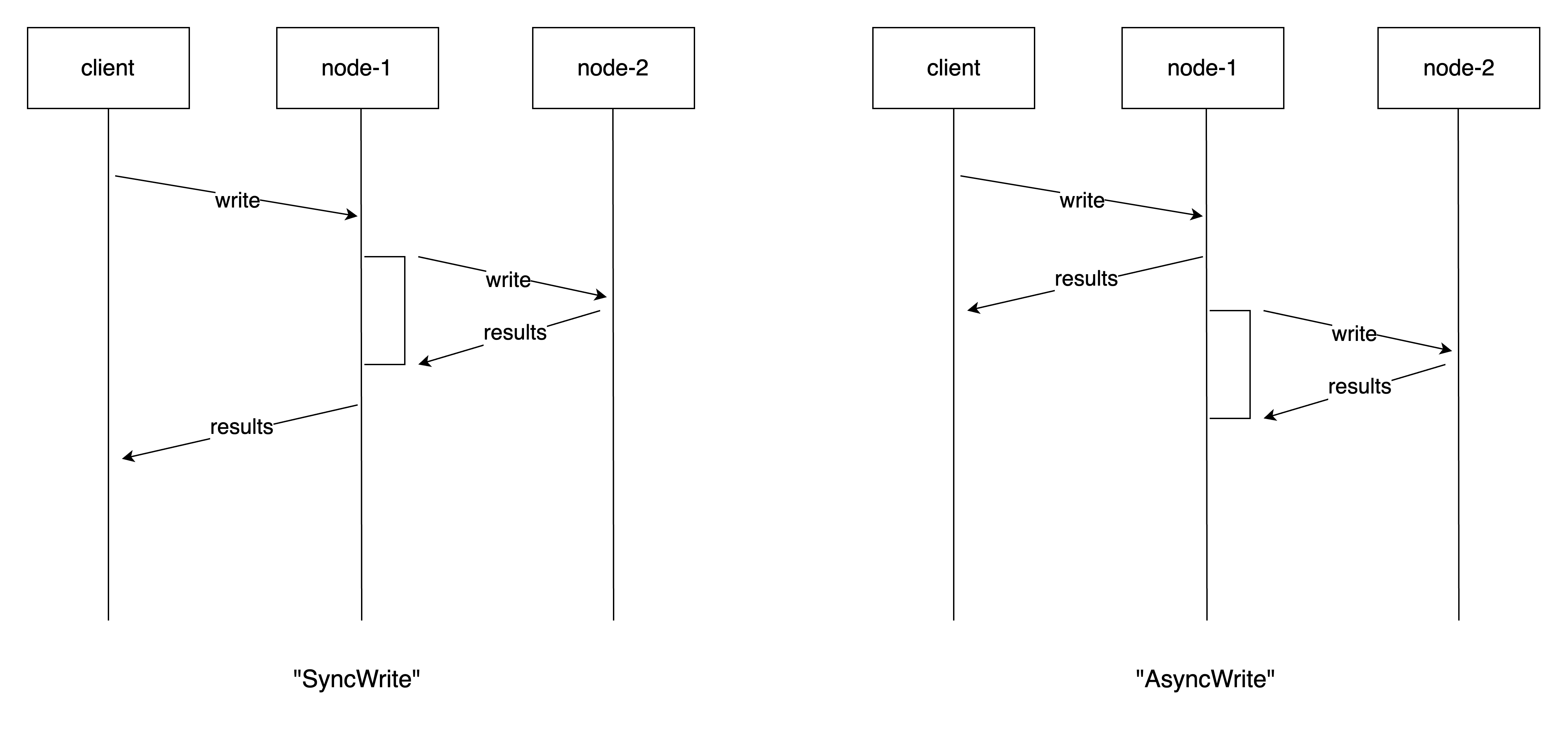
所以读写操作有四种组合,它们的 RPO 如下:
| RPO | SingleRead | DualRead |
|---|---|---|
SyncWrite | 0 | 0 |
AsyncWrite | 两节点之间的网络延迟 | 0 |
在 SyncWrite 模式下,由于两个节点之间的写操作是同步的,所以 RPO 总是 0,无论读操作是什么模式。然而,SyncWrite
要求两个节点同时正常运行以处理写操作。如果你的工作负载是读多写少,并且可以容忍一段系统不可用的时间来恢复两个节点的健康状态,我们建议使用 SyncWrite + SingleRead
组合。
另一个可以达到 0 RPO 的组合是 AsyncWrite + DualRead。这是上面所说的相反情况,适用于写多读少的工作负载,两节点可用性的限制要求可以降低。
最后一个组合是 AsyncWrite + SingleRead。这是对两节点可用性最宽松的要求。如果两个节点之间的网络状况良好,并且节点可以被可靠地托管,例如,两个节点托管在一个
AZ(可用区,或“数据中心”)内的虚拟机系统中,你可能更倾向这种组合。当然,只要记住 RPO 不是 0。
RTO
为了保持我们的双活互备架构的最低需求,我们没有要求第三个节点或第三个服务来处理 GreptimeDB 的故障转移。一般来说,有几种方法可以处理故障转移:
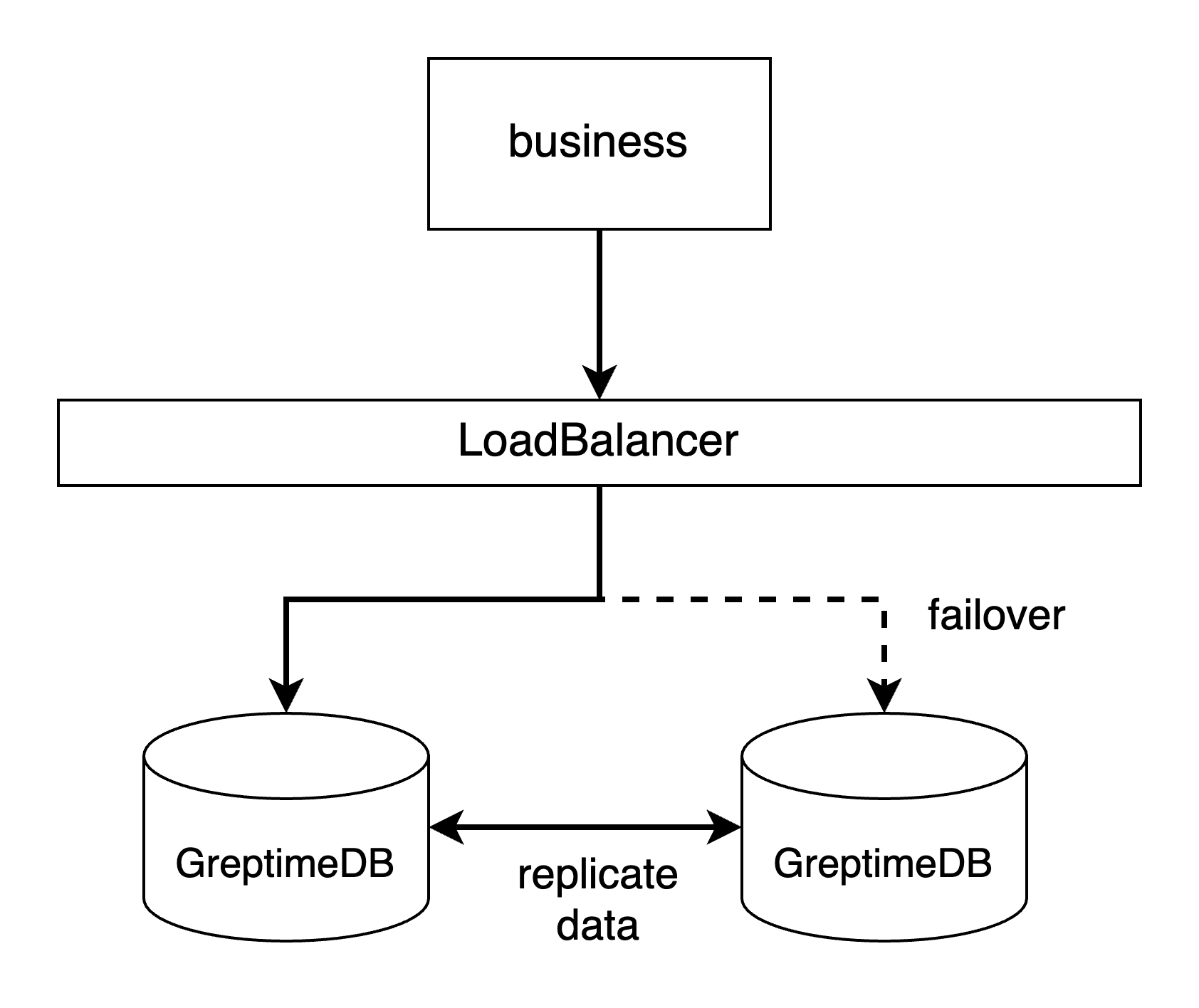
- 通过一个 LoadBalancer。如果你可以额外腾出另一个节点来部署一个 LoadBalancer
如 Nginx,或者你有其他 LoadBalance
服务,我们推荐这种方式。
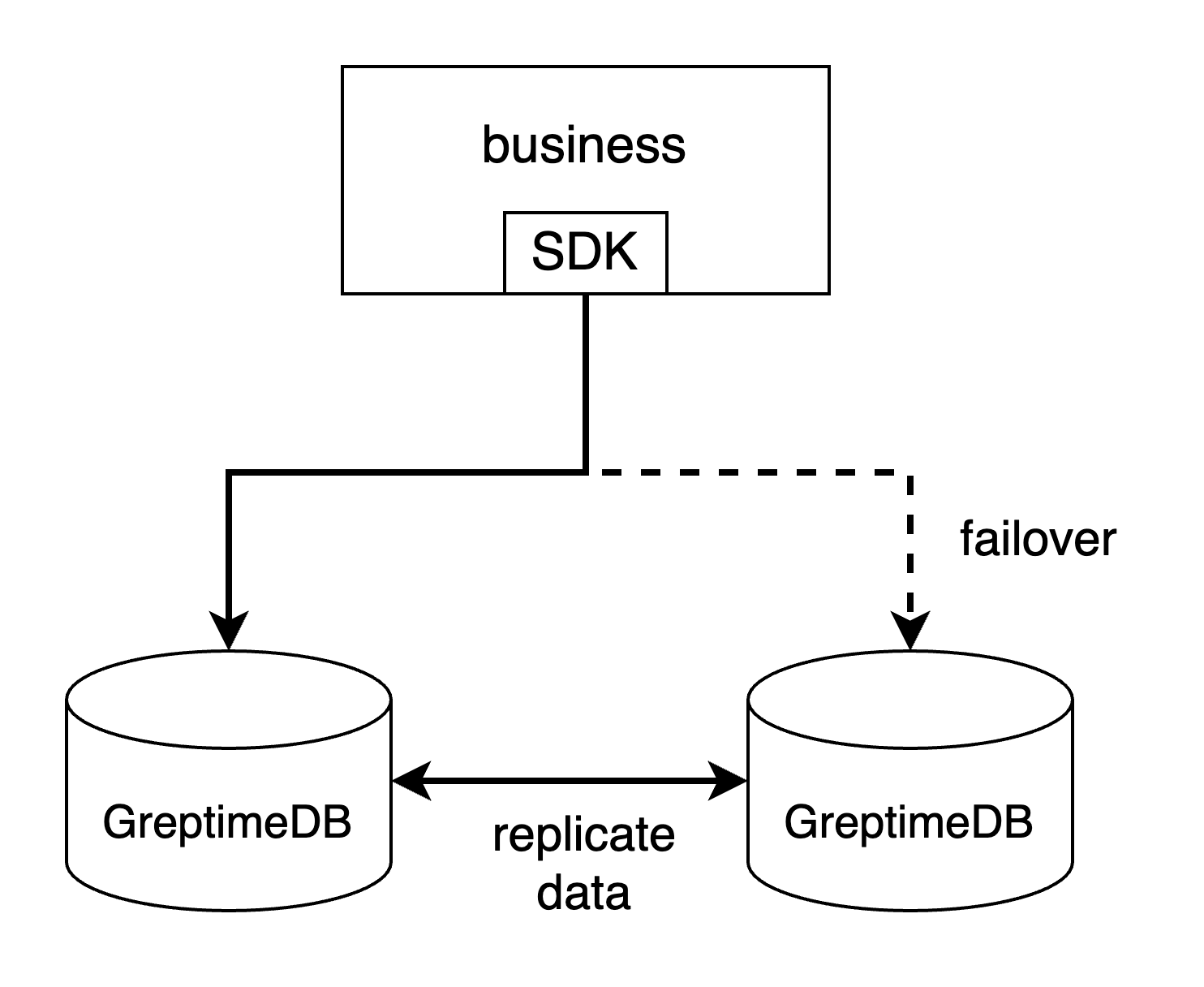
- 通过客户端 SDK 的故障转移机制。例如,如果你使用 MySQL Connector/j,你可以通过在连接 URL
中设置多个主机和端口来配置故障转移(参见其文档
)。PostgreSQL 的驱动程序也有相同的机制
。这是处理故障转移最简单的方法,但并不是每个客户端 SDK 都支持这种故障转移机制。
- 内部的 endpoint 更新机制。如果你可以检测到节点的故障,那么就可以在你的代码中更新 GreptimeDB 的 endpoint。
请参考 "解决方案比较" 来比较不同灾难恢复解决方案的 RPO 和 RTO。
总结
在 GreptimeDB 的“双活互备”架构中,你可以选择不同的读写模式组合来实现你的 RPO 目标。至于 RTO,我们依赖外部机制来处理故障转移。一个 LoadBalancer 是最适合的。