Region Failover
Region Failover provides the ability to recover regions from region failures without losing data. This is implemented via Region Migration.
Enable the Region Failover
This feature is only available on GreptimeDB running on distributed mode and
- Using Kafka WAL
- Using shared storage (e.g., AWS S3)
Via configuration file
Set the enable_region_failover=true in metasrv configuration file.
Via GreptimeDB Operator
Set the meta.enableRegionFailover=true, e.g.,
helm install greptimedb greptime/greptimedb-cluster \
--set meta.enableRegionFailover=true \
...
The recovery time of Region Failover
The recovery time of Region Failover depends on:
- number of regions per Topic.
- the Kafka cluster read throughput performance.
The read amplification
In best practices, the number of topics/partitions supported by a Kafka cluster is limited (exceeding this number can degrade Kafka cluster performance). Therefore, we allow multiple regions to share a single topic as the WAL. However, this may cause to the read amplification issue.
The data belonging to a specific region consists of data files plus data in the WAL (typically WAL[LastCheckpoint...Latest]). The failover of a specific region only requires reading the region's WAL data to reconstruct the memory state, which is called region replaying. However, If multiple regions share a single topic, replaying data for a specific region from the topic requires filtering out unrelated data (i.e., data from other regions). This means replaying data for a specific region from the topic requires reading more data than the actual size of the region's data in the topic, a phenomenon known as read amplification.
Although multiple regions share the same topic, allowing the Datanode to support more regions, the cost of this approach is read amplification during WAL replay.
For example, configure 128 topics for metasrv, and if the whole cluster holds 1024 regions (physical regions), every 8 regions will share one topic.
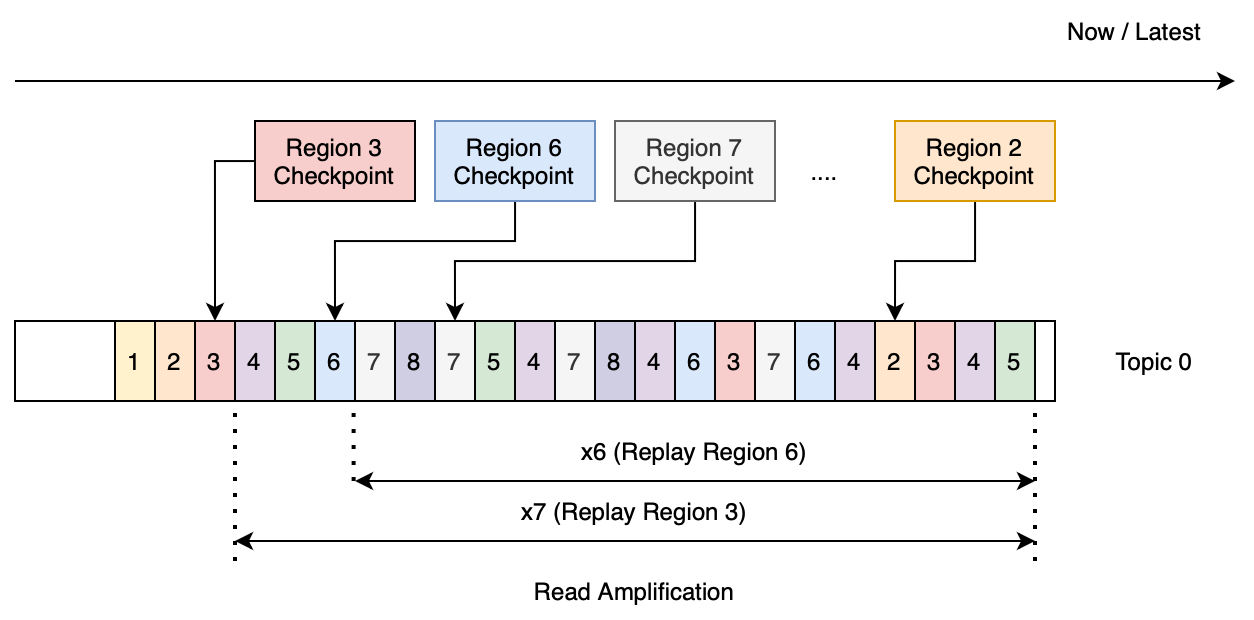
(Figure1: recovery Region 3 need to read redundant data 7 times larger than the actual size)
A simple model to estimate the read amplification factor (replay data size/actual data size):
- For a single topic, if we try to replay all regions that belong to the topic, then the amplification factor would be 7+6+...+1 = 28 times. (The Region WAL data distribution is shown in the Figure 1. Replaying Region 3 will read 7 times redundant data larger than the actual size; Region 6 will read 6 times, and so on)
- When recovering 100 regions (requiring about 13 topics), the amplification factor is approximately 28 * 13 = 364 times.
Assuming we have 100 regions to recover, and the actual data size of all regions is 0.5GB, the following table shows the replay data size based on the number of regions per topic.
| Number of regions per Topic | Number of topics required for 100 Regions | Single topic read amplification factor | Total reading amplification factor | Replay data size (GB) |
|---|---|---|---|---|
| 1 | 100 | 0 | 0 | 0.5 |
| 2 | 50 | 1 | 50 | 25.5 |
| 4 | 25 | 6 | 150 | 75.5 |
| 8 | 13 | 28 | 364 | 182.5 |
| 16 | 7 | 120 | 840 | 420.5 |
The following table shows the recovery time of 100 regions under different read throughput conditions of the Kafka cluster. For example, when providing a read throughput of 300MB/s, recovering 100 regions requires approximately 10 minutes (182.5GB/0.3GB = 10m).
| Number of regions per Topic | Replay data size (GB) | Kafka throughput 300MB/s- Recovery time (secs) | Kafka throughput 1000MB/s- Recovery time (secs) |
|---|---|---|---|
| 1 | 0.5 | 2 | 1 |
| 2 | 25.5 | 85 | 26 |
| 4 | 75.5 | 252 | 76 |
| 8 | 182.5 | 608 | 183 |
| 16 | 420.5 | 1402 | 421 |
Suggestions for improving recovery time
In the above example, we calculated the recovery time based on the number of Regions contained in each Topic for reference. We have calculated the recovery time under different Number of regions per Topic configuration for reference. In actual scenarios, the read amplification may be larger than this model. If you are very sensitive to recovery time, we recommend that each region have its topic(i.e., Number of regions per Topic is 1).